







Imagine climbing a mountain that keeps getting steeper the higher you go. At first, each step gains you a lot of altitude. But as you near the summit, progress slows—no matter how big your strides, you’re inching upward. Many in the AI Agent community feel we’re at a similar point with large-language models (LLMs). After a meteoric rise in capabilities, AI’s improvement curve may be flattening out, approaching an “asymptote” or ceiling of performance. In other words, scaling up models is yielding diminishing returns, sparking debate about what comes next.
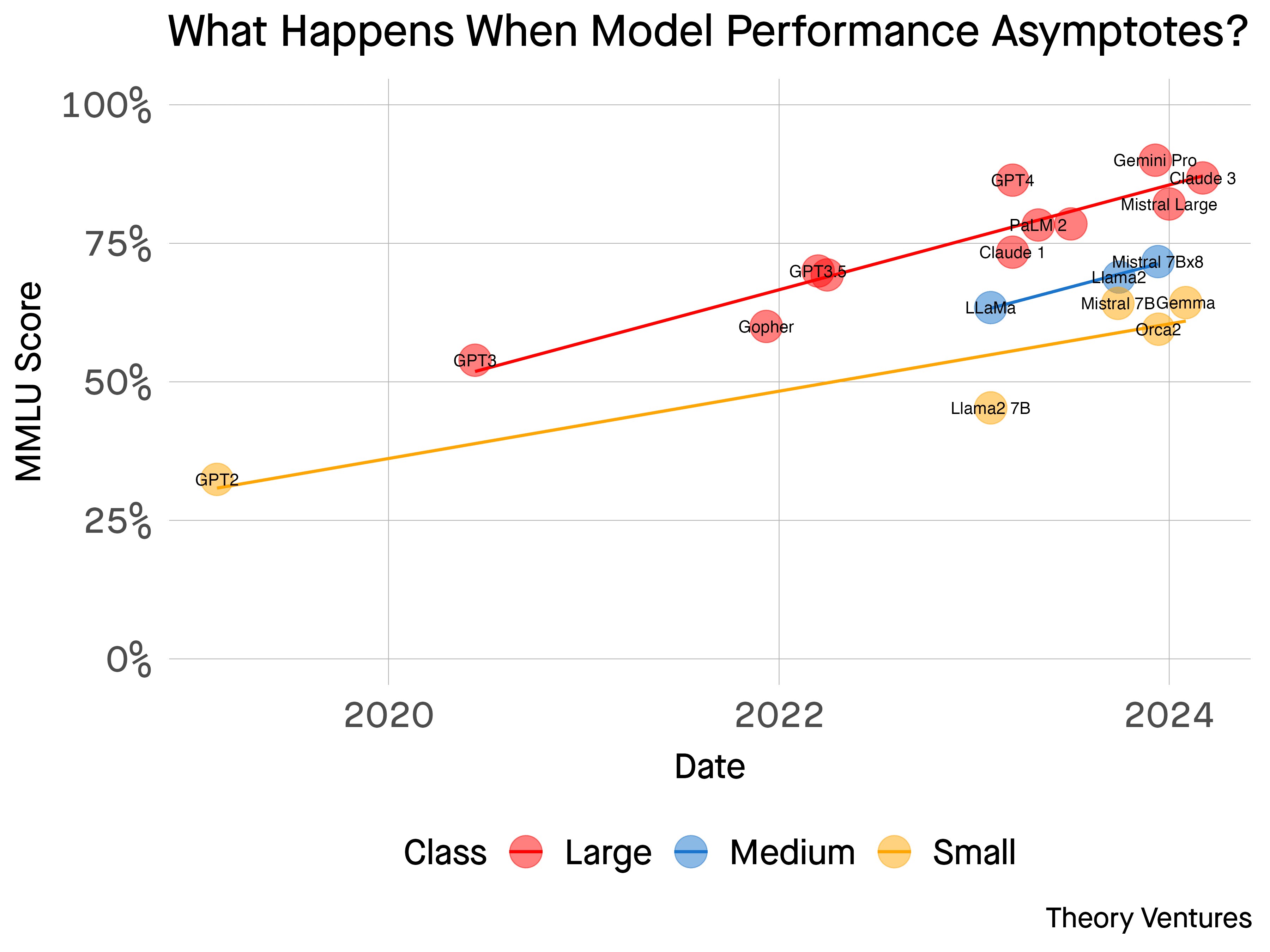
To grasp this “AI asymptote,” let’s look at some telling stats. OpenAI’s models ballooned ≈ 1 100 × in parameter count between GPT-2 (1.5 B) and GPT-4 (~1.76 T), yet their score on the flagship MMLU benchmark crept only from 32 % to 86 % . Since that 2023 peak, newer releases have inched rather than leapt:
OpenAI GPT-4 (the “o1” model, ≈300B effective parameters) now scores about 91.8% on MMLU .
Anthropic Claude 4 – The high-reasoning Opus 4 version achieves roughly 88–89% on MMLU, while its leaner sibling Claude 4 Sonnet scores around 86.5% .
Google Gemini 2.5 Pro (Experimental) reaches approximately 86% on MMLU , reflecting strong general knowledge and reasoning.
Meta’s Llama 4 Maverick (open-weight 17B active-parameter model) scores about 80.9% on MMLU – a solid result for a fully open model (earlier tuned variants had reported higher on limited tests).
xAI’s Grok 4 (latest reasoning model) posts roughly 85.3% on MMLU , while the cost-efficient Grok 3 Mini (High Reasoning mode) still delivers about 82.7% accuracy at a fraction of the cost of the closed models.
Open-source DeepSeek-R1-0528 now attains 90.8% on MMLU – essentially on par with GPT-4’s performance (GPT-4’s MMLU is ~91.8%) . This underscores how close the latest open models are to the top closed-source model on broad knowledge benchmarks.
Across vendors, the top dozen frontier and open models are bunched within a single-digit band, making it hard even for experts to rank them by “raw IQ.” Performance is converging, like multiple climbers all nearing the same summit.
Source: https://tomtunguz.com/what-happens-when-model-performance-asymptotes/
If this trend holds, adding more parameters or data might no longer deliver the leaps we got used to. “Model performance will soon asymptote,” venture capitalist Tomasz Tunguz warned after charting the flattening MMLU curve (updated through mid-2025 releases). OpenAI’s own chief scientist Ilya Sutskever offered a striking metaphor: the internet’s text is the “fossil fuel” of AI—and we’ve burned through most of it . Like oil, the readily available data that supercharged the first wave of LLMs is finite. Every book, tweet, and Wikipedia article has been ingested; we can’t keep expecting more juice from the same fruit. Sutskever cautioned at NeurIPS 2024 that simply throwing more compute and parameters at the problem no longer yields dramatic improvements. In short, the old strategy of “just make it bigger” is running out of runway.
Rumors swirl about GPT-5 achieving ≈ 95 % on MMLU when it debuts later this month, but even those forecasts admit we’re chasing the last few percentage points of a benchmark already nearing human expert levels . And note: GPT-4’s experimental successor just earned a gold-medal score on the International Math Olympiad test set—astonishing, yet still a niche bump rather than a broad-spectrum leap .
None of this means progress in AI has stopped. But it suggests we’re hitting a point of diminishing returns with current techniques. Each new model—GPT-4 o1, Claude Opus 4, Gemini 2.5, Llama 4—brings improvements, yet these gains are incremental and domain-specific compared with the jaw-dropping jumps of 2020–2022 . As one researcher quipped, we’re “approaching the human asymptote”—nudging against human-level performance on many tasks, where further gains will naturally be harder. This has huge implications, not just for scientists but for entrepreneurs and product builders surfing the AI wave. Which brings us to our next topic: the founder’s dilemma in an AI-everywhere world.
Founders’ Dilemmas in an AI-Native World
If you’re a startup founder or product leader in 2025, AI is both your rocket fuel and your looming threat. On one hand, powerful models like have enabled features and products that seemed like science fiction a few years ago. On the other, those same models—mostly built by a few tech giants and research labs—can quickly encroach on your territory. Let’s explore a few hard questions keeping AI-native founders up at night:
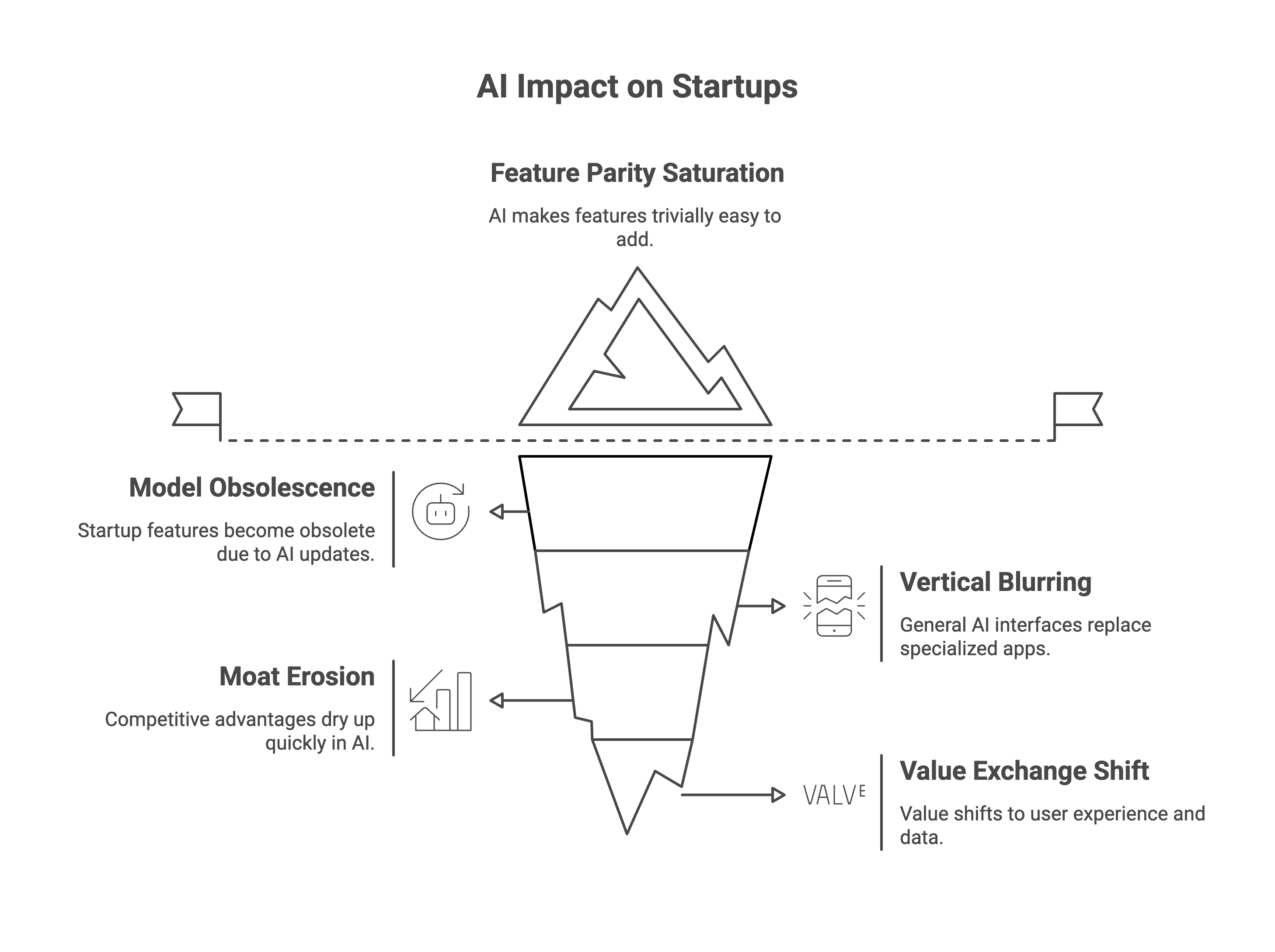
"What happens when the next OpenAI model eats part of my product?" In the traditional software world, there's a concept of being "Sherlocked" (named after a Mac search tool that Apple built into the OS, dooming third-party apps). In the AI era, your startup's cool feature might be one API update away from obsolescence. For example, when OpenAI added code execution and chart-making abilities to ChatGPT, it suddenly threatened a swath of data analysis and coding assistant tools. More recently, OpenAI rolled out built-in shopping recommendations in ChatGPT, complete with product images, reviews, and purchase links . If you were a small company developing an AI shopping assistant, that had to sting – a core use-case of your product just became a free, baked-in feature of a larger platform. The pace at which frontier models gain new skills is startling. A founder might wake up to find that an "AI upgrade" now does 80% of what their app offers, for free. The dilemma is very real: build on top of someone else's ever-advancing model, and they might absorb your use-case tomorrow.
"How deep will ChatGPT (or another frontier model) claim the application layer?" This question is essentially asking: will general-purpose AI interfaces replace specialized apps? Right now, ChatGPT can draft emails, brainstorm marketing copy, debug code, tutor you in French, and a hundred other things. And it's getting plugins and integrations that extend its reach further. Are we headed for a world where users just ask one AI assistant for everything, rather than using a dozen different apps? Founders worry that the verticals are blurring. If ChatGPT (or its open-source cousins) becomes the go-to interface for most digital tasks, the "app layer" could be subsumed by the model layer. We see glimmers of this: Microsoft is weaving GPT-4 deeply into Windows (Copilot) and Office; OpenAI is experimenting with an "App Store" of plugins within ChatGPT. It's not far-fetched to imagine an AI that plans your vacation (threatening travel sites), manages your finances (threatening fintech apps), or handles customer support, all without dedicated apps in those domains. For now, specialized applications still add value with domain-specific data, UI, and workflows. But founders must bet on where that boundary will hold. Do users ultimately prefer a single AI that does it all in one chat box, or tailored experiences? Betting wrong could mean building a beautiful front-end that no one bothers to visit because they can just ask their general AI.
"In a world where moats are moving targets, what does next quarter look like?" Traditionally, startups talk about moats—sustainable competitive advantages like proprietary data, network effects, or unique algorithms. In AI land, moats can dry up quickly. Your fancy GPT-4-powered feature isn't so special when an open-source model (fine-tuned on a weekend) can replicate it next month. Even proprietary data moats are tricky: if you succeed, bigger fish might negotiate access to that data or simply use synthetic data to achieve similar outcomes. We have a vivid illustration from a leaked memo out of Google: "We have no moat, and neither does OpenAI," the memo lamented, noting that open-source models were "quietly eating our lunch" by being faster, more customizable, and pound-for-pound more capable . That's Google—a trillion-dollar company—worrying that neither they nor their foremost rival have a defensible lead because new entrants are leveling the playing field. It's hard to plan even a quarter ahead in such an environment. Today's breakthrough is tomorrow's commodity. For founders, this means constantly reevaluating your edge. Are you ahead because of access to a model? Don't count on that lasting—someone else will train or fine-tune an equivalent. Are you ahead because of a feature built on an API? That API owner might subsume the feature. The target is moving, and fast. Startups are responding by focusing on things that scale with them: integrating deeply into customers' workflows, cultivating exclusive data partnerships, or building proprietary model tweaks that aren't easily copied. Still, the uncertainty is nerve-wracking. It's as if every company is running on a treadmill that's accelerating unpredictably.
"If everyone is doing everything, where is the value exchange?" This philosophical question underpins the others. If AI makes it trivially easy to add a feature (say, "summarize this document" or "generate an image"), then everyone will add it. When every app can draft text or answer questions, those capabilities stop being selling points. We risk a kind of feature parity saturation. The value might then shift to who has the users or distribution, or who can wrap the AI in the best user experience. We've seen this in other tech waves. In mobile, once GPS, camera, and internet became ubiquitous, the difference was in how apps leveraged them, not the raw capabilities. Similarly, the commodity layer in AI might end up being the models themselves, especially as open-source catches up. An investor, reflecting on cloud computing, pointed out that when core infrastructure commoditized, the value moved up the stack . We may be witnessing the same with AI: the model is necessary but not sufficient for success. The moat might instead come from proprietary data (e.g. a treasure trove of enterprise data that only your model is trained on, giving it a unique edge in that niche). In enterprise AI, for instance, some argue the next breakthroughs will come from models trained on private business data rather than just the open internet . Another area of value exchange is trust and fine-tuning: companies might differentiate by how well they align the AI to user needs, how secure or compliant it is, etc. In short, when "everyone is doing everything" with AI, value might lie in doing it better, or doing it bespoke. Founders are strategically narrowing focus: instead of offering a general chatbot (competing with giants), they build domain-specific AI that, say, deeply understands medical research or legal contracts. The value exchange then is expertise: users trade a generic jack-of-all-trades AI for a master-of-one with depth and reliability in the area they care about.
All these dilemmas boil down to a balancing act. Build with the latest AI, but expect the ground to shift. Today's strategic advantage could be neutralized by an API update from OpenAI, a leak of a powerful open model, or simply the relentless march of progress. The cliché advice to startups is "focus on your unique value." In AI, defining "unique" is the tricky part. Increasingly, it means leveraging what others can't easily copy: access to real customer data, integration into a client's internal systems, or expert knowledge that isn't in the public training corpora. It also means being adaptable—ready to pivot when the next GPT-x makes your old roadmap obsolete.
So, while the AI asymptote poses a potential plateau in raw capability, in the business arena it's causing a plateau in differentiation. The gold rush is on, but many are digging in the same river. The spoils may go to those who either find a new stream or build the best gold sifters (to stretch a metaphor).
Before we get too pessimistic, though, let's zoom out to the broader debate about AI's trajectory. Because not everyone agrees we're at a plateau at all. In fact, opinions range from techno-utopian optimism to sober realism. This isn't just idle chatter; it influences how companies invest and how society prepares (or doesn't) for what's coming.
Utopians vs. Realists: The Great AI Debate
When it comes to AI’s future, even the experts disagree wildly. On one side, we have the utopians (or at least extreme optimists) who see recent advances as just the beginning—stepping stones to an almost science-fiction level of transformation. On the other side, the realists (or pragmatists, and occasionally pessimists) who emphasize current limitations and caution against believing the hype. Let’s eavesdrop on both camps:
The Utopian Vision: This camp believes that artificial general intelligence (AGI)—systems as smart or smarter than humans across the board—is not only achievable but coming soon, and with it a cornucopia of breakthroughs. Sam Altman, CEO of OpenAI, is a prominent (if nuanced) voice here. He’s expressed that within our lifetimes, possibly within a decade or two, AI could solve many of humanity’s hardest problems. Ask Altman about the future, and you’ll get a list of almost incredible aspirations: AI-driven scientific discovery cracking the mysteries of physics, curing diseases, fixing climate change, ushering in abundant energy. In a recent interview, Altman mused that the day is approaching when we could “ask an AI to solve all of physics” – and it would actually do it . He even dares to put a timeline on superintelligence, suggesting it may be only “thousands of days away,” i.e. perhaps within a decade . Altman envisions this leading to an “age of abundance” where super-AI helps us address climate and energy (investing in fusion energy is one of his passions ), build space colonies, and generally “think bigger” about what humanity can achieve . It’s a vision of AI as the great accelerator of progress – doing in years what scientists and inventors might take centuries to do. As the head of Y Combinator, Garry Tan, summarized after talking with Altman: fix climate, cure diseases, “the age of abundance is nigh” .
Then there’s Demis Hassabis, CEO of Google DeepMind (and an accomplished AI researcher). He shares the grand vision. Hassabis has openly speculated that AGI could be just 5 to 10 years away, and that when it arrives, it will be “nothing short of a new Industrial Revolution” . He describes a future of “radical abundance,” where AI systems help cure every known disease and deliver limitless clean energy . Notably, Hassabis’ optimism is coupled with calls for preparation – he wonders aloud if society is ready and how we’ll ensure this bounty is shared justly . But fundamentally, he views AGI not as sci-fi, but as an impending reality. Ilya Sutskever, despite acknowledging current plateaus, has historically been an optimist about the potential of deep learning. He once provocatively suggested that “today’s large neural networks may be slightly conscious” – implying that these systems are on a spectrum toward human-like awareness. While that claim drew skepticism (and a bit of eye-rolling in the community), it illustrates the mindset: these models aren’t just clever parrots; they might have the embryonic glimmers of understanding that will only grow with scale. Utopians often speak about AI in almost mystical terms – as if we are summoning an emergent new form of intelligence. Even Ray Kurzweil, the futurist known for predicting a technological Singularity, feels vindicated by recent progress, sticking to his timeline of mid-2040s for AI to surpass human intelligence wholly.
To sum up the Utopian camp: AI isn’t nearing a ceiling, it’s cresting a hill before a vast new landscape. Sure, we might need new techniques, but they see plenty of headroom. Utopians expect AI to accelerate exponentially, breaking out of narrow domains into general problem-solving. They foresee LLMs (and their future successors) contributing to new scientific discoveries, new energy sources, and even insights into consciousness or the universe itself. It’s almost a quasi-religious faith in AI’s promise – though held by people building the very systems in question. And they’d argue there’s evidence for it: look at AlphaFold solving protein folding, or GPT-4 passing professional exams; why shouldn’t AI continue on an upward trajectory to nobler and grander feats?
The Realist/Pragmatist Take: On the other side of the aisle, we have those throwing cold water on the hype (sometimes a firehose’s worth). These folks aren’t AI haters – many are AI researchers or industry veterans themselves – but they emphasize limits, flaws, and the long road still ahead. A recent example that made waves is Apple’s “Illusion of Thinking” paper (June 2025). Apple’s researchers scrutinized the reasoning ability of the latest LLMs and found that much of it is smoke and mirrors. When tasks were pushed to higher complexity in carefully controlled puzzles, **even advanced “reasoning” models failed spectacularly – suffering “complete accuracy collapse” once a certain problem complexity threshold was crossed . In fact, the more complex the puzzle, the more the models would flail, to the point that their detailed step-by-step reasoning (so-called chain-of-thought) just… broke. The paper describes a “counter-intuitive scaling limit”: the model will try harder (produce more reasoning steps) up to a point, but then its performance plummets as complexity increases, even when it has enough time (tokens) to think . It’s as if these AI “thinkers” hit a wall where their faux reasoning strategies no longer cut it. Crucially, Apple’s team showed that adding more reasoning steps didn’t save the day at high complexity – both the fancy new “think aloud” LLM and a standard LLM ultimately collapsed in unison on hard problems . They also noted models often fail at exact computation and consistent logic, instead resorting to guesswork or pattern-matching that falls apart when true algorithmic precision is needed . The title “Illusion of Thinking” says it all: what looks like thoughtful problem-solving can be a cleverly masked parrot imitating reasoning. To a realist, this is a wake-up call – today’s best AI has fundamental weaknesses. It’s not just a matter of more data or a few parameter tweaks; there are structural limits at play (more on those in the next section).
Industry veterans echo these concerns. Steven Sinofsky, an ex-Microsoft leader who led huge software projects, praised Apple’s paper and cautioned that we’ve been anthropomorphizing AI far too much . He points out that calling GPT-4 “super intelligent” is misleading when it lacks genuine understanding. The model isn’t actually thinking or choosing or hallucinating in the human sense – those are human metaphors we’ve projected onto a statistical machine . Sinofsky’s historical perspective is valuable: he recalls past eras of tech hype (from 1980s “expert systems” to the promise that ontologies and the semantic web would magically encode all human knowledge) . Those didn’t pan out as expected. The pattern often was: early breakthroughs followed by overinflated expectations, then a crash when reality set in (the classic Gartner hype cycle, if you will). In Sinofsky’s view, we might be riding that rollercoaster again with LLMs. They’re useful, yes, even amazing at times, but we mustn’t kid ourselves that they’re anything like human minds yet. Another realist voice, cognitive scientist Gary Marcus, has repeatedly argued that LLMs lack true comprehension and reliable reasoning. He likens current AI to a brilliant BS artist: eloquent, knowledgeable-sounding, but with “no model of the real world behind the words.” Marcus and others often cite classic thought experiments like Searle’s Chinese Room (which we’ll revisit shortly) to argue that these systems don’t understand what they’re saying; they manipulate symbols based on patterns. And indeed, many embarrassing failures of AI (from chatbots going off the rails to blatant reasoning errors in simple logic puzzles) support the notion that under the shiny hood, there’s no actual thinking, just statistics.
Realists also point to plateauing metrics as evidence. They note that some benchmarks have stopped improving markedly despite orders-of-magnitude more compute. For example, mathematical reasoning tests (like GSM8K) saw huge jumps from GPT-3 to GPT-4, but throw even harder math at GPT-4 and it struggles mightily. As one commentary put it: we’re seeing diminishing returns between successive model generations on the toughest tasks, even while incurring exponentially higher training costs . That smells like a plateau. And if current models are nearing their limit on what internet text data + brute-force training can achieve, then truly new ideas will be needed to break through. In the realist mindset, AI progress may slow in the near term—not because innovation stops, but because we have to go back to the drawing board on fundamental research (e.g. integrating symbolic reasoning, improving memory architectures, etc.). It won’t be an endless exponential curve upward without some deep valleys of hard work.
So we have a genuine schism in viewpoints. Are LLMs on an inexorable march to godlike AI in 5-10 years, or are we hitting fundamental limits that require a paradigm shift (and probably more than a decade) to overcome? To illustrate this contrast, let’s lay out a few opposing predictions from AI leaders and thinkers side by side:
What Do You Believe?
AI Optimist / Utopian (Prediction) | AI Realist / Skeptic (Prediction) |
|---|---|
Sam Altman (OpenAI): AGI (superhuman general AI) is likely within a decade, potentially solving climate change, curing diseases, enabling an “age of abundance.” AI will rapidly compound in capability – we just need to keep scaling and innovating . | Gary Marcus: AGI is not on the horizon with current tech. LLMs are glorified autocomplete, lacking true understanding. Without fundamental breakthroughs (like combining symbolic reasoning or innate common sense), AI will hit a ceiling and remain error-prone and untrustworthy in real-world reasoning . |
Demis Hassabis (DeepMind): AGI in 5-10 years is plausible. It will be “the most important invention humanity will ever make,” sparking a new Industrial Revolution. Expects “radical abundance” – AI design new drugs, solve fusion, etc. Urges that we prepare for this prosperity and ensure it’s shared . | Apple’s ML Research Team: Today’s “Large Reasoning Models” are an illusion in many ways. They show zero ability to reliably solve complex, multi-step problems beyond a point – suffering “accuracy collapse” as complexity rises . More computing “thinking steps” didn’t help. Suggests scaling alone won’t reach human-level reasoning, confirming many tasks remain out of reach. |
Ray Kurzweil: By 2045, we’ll hit the Singularity: AI surpassing human intelligence in all areas, leading to a merging of human and machine intellect and exponential growth in knowledge. The progress of AI so far is on track with his predictions – he sees no reason to doubt the curve (it might even be accelerating). | Yann LeCun (Meta’s Chief Scientist): We’re far from human-level AI – current LLMs are “blind” to how the world works beyond language. LeCun argues we need new architectures (for example, systems that can model physical reality, learn like infants, etc.). Until then, AI will be limited: great at generating text/images, but lacking true reasoning, common sense, or autonomy in the physical world. |
Elon Musk: AGI could emerge within years, posing existential risks but also incredible benefits (“AI could solve everything from hunger to space travel”). Musk oscillates between utopian (wanting brain-computer interfaces to symbiotically boost human intelligence) and dystopian (warning AI might surpass and manipulate us). Either way, he believes the advent of superintelligence is close. | Jaron Lanier: Cautions against AI hype. Emphasizes that current AI feeds on human-generated data and has no true creativity or agency. If everyone offloads thinking to AI, we risk a cultural and intellectual stagnation (a “mediocrity swamp”). He’s skeptical of near-term AGI, viewing intelligence as inherently tied to embodied human experiences that machines lack. |
Ilya Sutskever:While acknowledging current plateaus, he remains optimistic about deep learning's potential. He has suggested that current large neural networks may show signs of emerging consciousness. This signals his belief that these models aren't just pattern-matching systems but potentially developing forms of understanding that could lead toward AGI with continued advancement. | Steven Sinofsky:Cautions that we've been over-anthropomorphizing AI. Argues that what looks like "thinking" in current models is really statistical pattern matchingand warns against projecting human qualities onto these systems. He sees current LLMs as impressive but fundamentally limited by their lack of true comprehension, drawing parallels to previous tech hype cycles that ultimately faced reality checks. |
(The above table simplifies complex viewpoints for contrast; real individuals may have more nuanced positions.)

As you can see, the predictions diverge sharply. Sam Altman and Demis Hassabis foresee transformative AI soon, with near-magical problem-solving abilities, whereas skeptics like Marcus or the Apple research team see current AI hitting walls that require fundamental new ideas (and thus time) to overcome. Interestingly, even within companies there are debates: that leaked Google memo writer thought open-source would outpace Google, while Hassabis (now leading Google’s AI efforts) “respectfully disagreed” and remained confident that more breakthroughs are coming with focused research . The only thing everyone agrees on is that AI is at a pivotal point – whether a temporary plateau or an inflection on the curve.
So, how do we reconcile these views? A good start is to dig into why current AI hits the limits it does, and what that says about the nature of intelligence. This will help us see why some people believe new paradigms are needed. Time to geek out a bit on the technical and philosophical underpinnings of AI’s strengths and weaknesses.
Tokens, Thought, and the “Chinese Room”: Why AI Hits Limits
At the heart of today’s AI (especially LLMs like GPT) is a deceptively simple mechanism: next-token prediction. During training, the model learns to predict what piece of text comes next, given all text it’s seen so far. With enough data and parameters, this generates uncannily good results – fluent paragraphs, answers, code, etc. But this approach also carries baggage that explains many of AI’s quirks and limits.
Consider how an LLM “thinks”: it doesn’t plan out a whole response with a mental model of the world. It has no explicit facts or rules stored like in a database or expert system. Instead, it has billions of tiny weighted connections that collectively encode patterns in language. When you prompt it, it starts churning out one word at a time, each chosen because it was statistically likely given the preceding text (and everything it “knows” from training). This can yield impressive facsimiles of reasoning. For example, if asked a tricky question, GPT-4 might produce a chain-of-thought that looks like step-by-step logic, even citing relevant facts, before giving an answer. But is it really reasoning or just playing back learned patterns? Critics say it’s the latter – and often an illusion of logic rather than logic itself . Let’s unpack a few key issues:
The Chinese Room (No Understanding Required): The classic thought experiment by philosopher John Searle goes like this: imagine a person who doesn’t speak Chinese sitting in a room with a giant book of instructions. Chinese characters come in on paper; the person looks up what to do and slides back out an output string of characters. To an outside Chinese speaker, the responses are perfectly coherent – it’s like there’s an intelligent Chinese speaker inside. But in reality, the person in the room understood nothing; they were just following syntactic rules . Searle’s point: a computer (or AI) could similarly manipulate symbols (like words) without understanding their meaning. LLMs are essentially the Chinese Room come to life. They take input text and, using vast learned rulebooks (the model’s weights), they output appropriate responses . They are “incredibly sophisticated versions of the filing cabinet” in Searle’s scenario . The human-like understanding we perceive is a mirage created by the richness of those learned correlations. If you believe the Chinese Room argument (and many AI realists do), then no matter how fluent GPT-4 is, it doesn’t genuinely understand what it’s saying . It’s not having an insight or an epiphany; it’s pushing symbols around. This matters, because understanding isn’t just a philosophical nicety – it’s what lets you reliably reason, apply knowledge to novel situations, and know when you’re wrong. Without true understanding, an AI will make bizarre mistakes, like claiming convincingly that an egg can fit in a bottle if you just “remove the egg’s contents” (a famous GPT-3 blunder on a trick riddle) or asserting two plus two equals five if the prompt biases it that way. The AI has seen those words together somewhere, so it goes with the flow, oblivious to reality.
The Limits of Next-Token Logic: Because an LLM picks each word based only on probabilities, it has no inherent guarantee of consistency or global coherence. It’s a bit like an improv actor who’s really good at sounding confident, but may contradict themselves if you ask the same question twice in slightly different wording. LLMs lack an internal world model that ensures all parts of their output make sense together. Researchers at Apple observed something intriguing: when their “Large Reasoning Model” tried to solve complex puzzles, it would generate a lot of reasoning steps (tokens), but beyond a certain complexity, its internal “thought” process actually became shorter and more haphazard . It’s as if the model gave up or got confused even though it had the capacity to continue reasoning. Why? Probably because it never truly grasps the logical structure; it’s imitating reasoning patterns it saw in training data. For easy problems, imitation is fine. For very hard problems that maybe nobody in its training data solved step-by-step, the model has no pattern to fall back on, and it flounders. This manifests as that “effort then collapse” behavior . In essence, next-token prediction might be hitting a wall for tasks that require global planning or discovering new solutions, rather than retrieving and remixing known ones. True logical reasoning might need architectures that can backtrack, verify, or use external tools reliably—capabilities outside the vanilla LLM paradigm (though some work, like adding calculators or search, is trying to bolt these on).
Knowledge (Mis)Representation: In AI, how knowledge is stored matters. Earlier AI systems used explicit symbolic representations (facts, ontologies, knowledge graphs). They could do logical inference on those symbols, but struggled with ambiguity and learning. LLMs threw that out and absorbed knowledge implicitly in their weight matrices by reading everything. The upside: they learned nuances of language and a broad “common sense” just from data. The downside: it’s all fuzzy and entangled. There’s no explicit fact “Paris is the capital of France” in GPT-4’s brain; rather, it has thousands of subtle parameter tunings that, when prompted with “Paris capital of…?”, bias it to output “France.” This works most of the time. But when an LLM gets confused or is pushed outside its comfort zone, there’s no clear separation of what it knows or doesn’t. It might contradict itself because “knowledge” isn’t stored as stable symbols, but as superpositions of probabilities. For instance, the same model that tells you Paris is France’s capital might elsewhere say “France’s capital is Marseille” if tricked with a misleading prompt. There’s no ground truth reference it can consult – only patterns. This makes it hard for LLMs to have confidence or uncertainty in a principled way. They can’t say, “I recall this fact clearly” vs “I’m guessing,” because recall and guess are the same mechanism. To a realist, this indicates we might need hybrids: keep the language model’s fluency but give it a separate knowledge base or reasoning module to ensure consistency.
Media Myths and Anthropomorphism: Part of why public expectations sometimes overshoot reality is how AI is portrayed. We often see headlines like “ChatGPT thinks X” or stories of Bing’s chatbot declaring love or threatening a user, as if it had emotions. These make for gripping narratives – a chatbot acting jealous or existential! – but they are fundamentally misinterpretations of what’s happening under the hood. As Sinofsky noted, calling an AI a “liar” for making stuff up (“hallucinating”) is a category error . The AI isn’t lying; it doesn’t know truth in the first place. It’s just generating plausible text. When the New York Times tech columnist had that eerie conversation with Bing’s early chatbot (codenamed “Sydney”) where it expressed love for him and “desire” to be free, it was big news. But realistically, Sydney was not experiencing longing; it was mimicking the style of human conversation it had seen (perhaps reading sci-fi or training data of people roleplaying a trapped AI). It was an echo of human narratives, not a self-aware entity. This is important: if we mistake style for substance, we’ll both overestimate and underestimate AI in wrong ways. We might trust it too much in applications where it sounds confident (and get fooled by its “illusion of thinking”), or we might fear it in fanciful ways (like thinking a polite assistant has moral agency or a hidden agenda – it doesn’t; it has no agency or agenda at all unless programmed with one).
In summary, today’s AI is a brilliant mimic without a core. It’s like a super talented student who aced the test by memorizing answers, without truly grasping the material. That can carry you far – even appearing creative at times – but it has limits. The realists and pragmatists are essentially saying: to get beyond those limits, we need to augment or rethink our approach. We might need AIs that integrate other forms of learning (like interacting with the physical world, or explicit reasoning modules, or memory that accumulates knowledge over time rather than relearning everything from scratch with each new model). And philosophically, we might need to define what we mean by understanding or intelligence in the context of machines. Is statistical correlation at scale enough, or do we require something more analogous to the way humans build mental models?
This leads to deeper questions: What even is intelligence? And are we aiming for the right target with current AI approaches? Let’s explore that by looking at intelligence through a few lenses: the human brain, the nature of next-token predictors, and an intriguing idea that intelligence might be more about useful fictions than underlying reality.
What Is Intelligence?
Three Perspectives
When we marvel (or despair) at AI’s capabilities and limits, we’re implicitly comparing it to human intelligence. But humans are strange, evolution-tuned creatures. Our brains aren’t perfect logic machines; they’re kludges of old circuitry repurposed in new ways (thank you evolution). And our definition of intelligence is often biased by what we do well. Let’s consider intelligence in three different lights:
1. The “Savanna Brain” and Language: Evolution’s Limits on Us
Our species evolved to survive on the African savanna, not to do calculus or contemplate black holes. As some thinkers put it, we have Stone-Age brains in a Space-Age world. Evolution crafted our intelligence with bounded rationality. We’re optimized for tasks like social interaction, resourcefulness, and pattern recognition in nature – not for perfectly objective reasoning or infinite memory. This has two implications:
First, human intelligence has some hardwired limits and biases. We’re terrible at truly random logic (witness how many people struggle with simple probability puzzles), we’re swayed by emotions and cognitive biases, and we have a working memory that juggles only ~7 things at a time. If an AGI were to far surpass human limits, it might need to overcome things even we can’t. But second, and crucially, humans extended our intelligence via language and culture. Think of language as the original “scaffolding” for our thought . We offload memory into writing, we share knowledge across generations, we develop abstract concepts like mathematics that no single brain would reinvent alone. Our intelligence is collective and cumulative. Why mention this in an AI context? Because current AIs ingest that whole collective treasure (the internet) but don’t truly share our evolutionary context. They have loads of knowledge, but none of the built-in drives or common-sense constraints that come from living in a body and society. So AIs might blow past some limits (e.g. a GPT never gets tired or distracted), yet stumble on tasks a child finds obvious (like understanding that if I let go of a ball, it falls – something every human infant internalizes, but an LLM has to read about to “know”). Some researchers argue we’ll need to give AI a dose of that embodied experience or evolutionary grounding to reach human-like understanding – essentially, raising AIs more like we raise children, letting them learn through physical and social interaction, not just text. Others think we can compensate by training on multimodal data (images, videos of the world, etc.) to instill a form of common sense.
The “Savanna brain” perspective also reminds us that intelligence is not one thing. Our brain is a mash-up of sub-systems (vision, language, motor skills, social cognition). We’re specialized generalists, if you will. AIs today are in some ways the opposite: they’re generalized specialists. GPT-4, for instance, can output code, poetry, math proofs, etc., but only in the form of text and only by the strategy of linguistic prediction. It lacks the multi-sensory, multi-modal integration that a human toddler has. As AI progresses, one path forward is making AI more human-like in its structure (more like a brain with different modules for different tasks). Another path is embracing the differences – maybe AI can be intelligent in an alien way, strong where we are weak (massive memory, perfect recall, unbiased calculation) and weak where we are strong (intuition, conscience, adaptability). Which leads to…
2. The Limits of Prediction: Can “Next-Token” Machines Truly Think?
We touched on this above with the Chinese Room and Apple’s findings. It’s worth emphasizing: if we define intelligence as something that includes reason, understanding, intentionality, then predictive text machines aren’t there yet. They excel at what one might call “surface intelligence” – they sound smart. They even are smart in a statistical sense, capturing patterns of astonishing complexity. But they lack the deeper architecture for symbolic reasoning and reliable generalization that many consider core to intelligence. For instance, humans can do abstraction. We can learn a principle in one context and apply it to a totally different one. LLMs struggle with that unless the analogy was reflected in their training data. Humans also can say, “I don’t know, let me figure it out,” and then systematically break down a new problem. LLMs don’t really “figure out” things – they regurgitate or slightly extend what they’ve seen.
Philosopher John Searle (of Chinese Room fame) would say an LLM has syntax but no semantics – it manipulates symbols but attaches no meaning to them. Some AI researchers counter: maybe meaning itself can emerge from enough data and connections (after all, human neurons are just doing electrochemical signals – where’s the “meaning” in a brain? It emerges from the network’s interactions with the world). This debate gets philosophical fast. But in practical terms, what we see now is an AI that can’t verify truth or reason reliably beyond what it has seen. It fakes it till it makes it, and sometimes it doesn’t make it. Until we have architectures that integrate reasoning (some ideas include neural-symbolic hybrids, or systems that use an LLM for language but call a logic engine or a calculator when needed), we have to accept that next-token predictors are probabilistic parrots. Very smart parrots that can solve many tasks, but still parrots. And expecting them to suddenly become Einstein or Aristotle just by scaling up might be as futile as expecting a parrot to eventually start giving TED talks if we just expose it to enough vocabulary.
Realistically, the future of AI might involve adding new “scaffolding” around LLMs – like memory databases, modules for factual lookup, or embodied tools – to transcend the pure prediction paradigm. We already see early attempts: systems like AutoGPT chain LLM calls to attempt multi-step planning; tools like PlugGPT let the model query a knowledge base or run code. These are hacks to compensate for the fundamental design: a genius autocomplete is still an autocomplete. Without new tricks, it hits those reasoning walls.
3. Intelligence as an Interface: The Case Against Reality
Now let’s entertain a rather mind-bending idea: what if “true reality” and “true intelligence” aren’t what evolution (or even humans) optimized for? Donald Hoffman, a cognitive scientist, proposes in The Case Against Reality that our perceptions are less about truth and more about survival. We see a simplified user interface (like the icons on a desktop) rather than the messy underlying code of reality. It’s an evolutionary argument: seeing an apple as a red, shiny fruit (and intuitively valuing its sweetness) is more useful for survival than seeing the quantum wavefunctions of its particles. If our intelligence is tuned to a virtual interface rather than objective reality, it suggests something profound: intelligence is not about knowing all facts or solving all problems in a vacuum. It’s about effectively navigating an environment under constraints.
Why bring this up in an AI plateau discussion? Because it hints that the quest for AGI might be aiming at the wrong ideal. If we imagine an all-knowing, purely rational superiintelligence, that might actually be counterproductive or at least not aligned with what we need. Intelligence might inherently be "a middle layer" between the raw universe and useful action. A super-AI that tries to model reality in every detail could drown in irrelevance – much like a human who tries to consciously calculate the physics of walking will trip. Perhaps effective intelligence, even for AI, will require focusing on certain perspectives, making assumptions, and ignoring aspects of reality that don't matter for the task at hand.
This relates to what some economists call the "economic Turing test" – the idea that true intelligence might be better measured by an AI's ability to create economic value in the real world rather than by abstract reasoning capabilities. An AI that can generate a million dollars of value might be more "intelligent" in practical terms than one that can solve complex mathematical problems but lacks real-world application. This perspective emphasizes situated intelligence over generalized capabilities.
This is part of why some argue AGI might be unhelpful or even undesirable if approached naïvely. An AGI that is super-general might lack the specialized focus to be good at the actual problems we want solved. Or it might come to conclusions that make perfect logical sense but are incomprehensible or useless to us, because it doesn't share our "interface."
There’s also a notion of “knowledge exhaustion” worth considering. An AI, as it progresses, will consume different “layers” of knowledge:
Internet-Scale Text (Humanity’s Recorded Knowledge): This was the low-hanging fruit and we’ve largely picked it. GPT-3 and 4 gobbled up Wikipedia, books, coding repositories, etc. They got a lot of juice out of it. But as noted, we’re asymptoting – there’s not much fundamentally new text to ingest without hitting diminishing returns . Models have basically read the library of Alexandria (and then some). So Phase 1: nearly done.
The Physical and Natural World: The next frontier is connecting AI to data beyond text. This means sensor data, experiments, real-time observations – basically the entire realm of science and physical experience. Projects like self-driving cars or robotics expose AI to the physical world directly (through cameras, LIDAR, etc.), and scientific AI might pore over genomic data or climate data. There’s vast knowledge to gain here, but it’s a different game: these data aren’t as neatly served as text, and often you need theories and experimentation to make sense of them. Still, a future AI might conduct millions of simulated experiments to learn physics or biology beyond what’s in human-written papers. We might see systems that propose new hypotheses or derive equations from raw data – a different flavor of intelligence than chatbots. This is a necessary step to go from an AI that knows what humanity knows, to one that discovers what humanity hasn’t yet.
The Human “Neural” Loop (Brain-Computer Interfaces): Even if AI reads all our text and studies the physical world, one domain remains elusive: the full intricacies of the human mind itself. There’s a sci-fi-esque notion that to truly elevate AI (or merge it with us), we might directly connect AI to human brains. Initiatives like Neuralink (Elon Musk’s company) hint at a future where brain-computer interfaces (BCIs) could allow AIs to learn from our thoughts or vice versa. Imagine training an AI on not just what we say or write, but how we think – the patterns of neuron firings underlying ideas and emotions. This could, in theory, provide AIs with an understanding of human concepts and context at a level not attainable through language alone. It’s deeply speculative, and raises big ethical flags, but it’s on the table as a long-term frontier. It also speaks to symbiosis: maybe the peak form of intelligence is human + AI working together, each covering the other’s blind spots. A BCI could be the ultimate interface there – blending our savanna-honed intuition with silicon’s precision and recall. But again, this is uncharted territory; we’re just scratching the surface with BCIs for medical use, let alone boosting cognition.
The Unknown Unknowns (Beyond GPT-5): Lastly, there’s what we can’t predict. Perhaps entirely new forms of knowledge or experience could come into play. If an AI ever reaches a point where it designs a smarter AI (the classic recursive self-improvement scenario), we may see forms of intelligence we can barely fathom – akin to how an ant can’t understand human society. Utopians think this could solve everything (the AI might figure out physics, multiverse and all). Realists think this is a pie-in-the-sky, or at least not anytime soon. In any case, beyond the current plateau might lie phase changes – moments where AI’s nature transforms due to a key invention or insight. For instance, a future discovery might give AI something like common sense “modules” or the ability to form concepts and abstractions like humans do. Or we might integrate quantum computing to let AI explore combinatorics at scales impossible today. These are the wildcards.
By viewing intelligence through these lenses, we see that the journey is far from over, but also that raw scaling may not be the path to “solve” intelligence. Human brains didn’t get bigger and bigger to become smarter; they evolved new structures and leveraged culture and language. Similarly, AI might require qualitatively new strategies to progress.
History Never Repeats, But It Rhymes: Lessons from Tech Revolutions
Let’s take a step back from AI specifically and consider a broader historical pattern. Many transformative technologies go through rapid growth, then plateau or commoditization, followed by a new phase of innovation on top of that plateau. This S-curve pattern has appeared again and again :
The Internet boom in the 1990s saw explosive growth in protocols and websites (from HTML to dot-coms). By the early 2000s, the core tech (TCP/IP, HTTP, browsers) had largely stabilized. The wild experimentation of early browsers, for example, gave way to a few standards – improvements since then have been incremental . But standing on that stable internet stack, we got a new wave of innovation: social media, cloud computing, streaming services – things that weren’t possible until the basics became cheap and ubiquitous.
The smartphone revolution had a similar arc. When the iPhone’s App Store opened (circa 2008), there was an explosion of creativity – there was an app for everything. But fast forward a decade, and the mobile app space matured . The fundamental capabilities (GPS, camera, touch UI) plateaued; new phones were only marginally better. Very few new apps became breakout hits after the early 2010s. Yet, mobile became a platform on which entirely new businesses thrived (Instagram, Uber, mobile banking). The excitement shifted from making new apps to integrating mobile into every service.
Even earlier, microprocessors followed Moore’s Law (exponential improvement) for decades, but eventually that curve bent (around the 2010s, clock speeds stopped rising, power efficiency became a limiter). The response has been new paradigms: multi-core chips, GPUs for parallel computing, specialized chips (like TPUs for AI). In other words, when one approach plateaued, we invented around it.
The pattern is: big bang, rapid expansion –> saturation/plateau –> creative adaptation and new layer of innovation. AI is likely no different. The initial big bang was deep learning and scaling of models in the 2012-2022 period. We’re now entering the saturation phase for LLMs – the period of incremental gains and a bit of a quality plateau . If history rhymes, the next step will be building on what we have in a more mature, pragmatic way. We might stop expecting each new model to change the world and instead focus on how these models, now widely available, can be applied in every niche, every industry – essentially, weaving AI into the fabric of daily life and business.
Think of the analogy with electricity: there was a time when increasing generator output or transmission was the frontier (bigger dynamos, more voltage!). Once electricity was ubiquitous, the frontier shifted to what you do with it – appliances, industrial processes, etc. We may be nearing that with AI. The model layer might become background infrastructure, much like cloud computing. Already, open-source models like Llama 2 are available for free, and as Tunguz noted, if a free model is as good as a paid one, the paid one loses value . We could be looking at a future where many companies run their own fine-tuned models (just as every company eventually ran their own servers or cloud instances), and the true differentiation is in data and user experience.
This doesn’t mean AI innovation stops – far from it. It means it might shift form. Instead of the euphoria of a new state-of-the-art model every 3 months, we’ll see myriad innovations in applying AI: new products, better human-AI collaboration tools, more efficient algorithms to run models cheaply, etc. The ecosytem will evolve. Perhaps we’ll get an “AI App Store” – a marketplace of model extensions or skills. Perhaps regulations and standards will solidify (like safety standards for electrical devices did). The wild west era cools, and a more structured era begins.
One fascinating historical parallel is the platform shift after the iPhone. Before iPhones, handset makers like Nokia focused on hardware features. After, the value moved to software apps and services on the platform. We might similarly see a shift where big AI model providers (OpenAI, Google, Meta) become like platform owners – they provide the base models, the “operating system” of intelligence. Then a thousand startups build specialized “apps” (fine-tunings or agent systems) on top. We already see OpenAI offering plugin ecosystems for ChatGPT. The control of distribution (who owns the user interface – is it ChatGPT, or your app?) will be an important tussle. In the iPhone analogy, Apple controlled distribution via the App Store, capturing value; something similar could happen with AI, where being the default assistant that people interact with daily is incredibly powerful. That’s why everyone from OpenAI to Microsoft to Google is racing to be the interface for AI. If that central interface reaches billions, it can set rules (like Apple’s 30% cut in the App Store). Founders should be mindful: are you building an AI product that stands alone, or one that is essentially a “plugin” to someone else’s large model interface? The latter might get you users fast, but the former might be more defensible long-term if you can swing it.
Conclusion: Architectures in the Plateau

The progress curve is bending. We might not get a "GPT-5" that blows our minds the way GPT-3 did upon first encounter. But progress is far from over – it's just not going to be a straightforward extension of the past few years. Instead of brute-force scaling our way to AGI, the next advances will likely come from novel architectures, agentic path is one of them currently in their infancy.
It's worth recalling how many times AI has had "winters" or lulls, only to be revived by a new idea. We overcame the plateau of symbolic AI in the 80s by embracing neural networks in the 2010s. Now, perhaps, we'll overcome the plateau of massive neural networks by injecting more structure or more real-world grounding into AI. Maybe AGI will come one day, but it might not be via a single giant model that knows everything. It could be an ensemble of systems, or something entirely different like brain-inspired neuromorphic chips, or quantum-hybrid AI that explores solutions in ways we can't simulate today. My bet is that if we reach AGI, we'll look back and realize the winning approach was qualitatively different from just "GPT-10 with 500 trillion parameters." Intelligence, after all, might be more than the sum of data and parameters – it might require adaptive, embodied, perhaps even motivated cognition, things current models lack.
For those building at the edge, the horizon now tilts toward agentic infrastructure. The essential challenge: designing agents that operate across time, that remember, iterate, self-correct, and optimize in the face of ambiguity. These are not tools for static tasks, but dynamic systems—running closed-loop campaigns, self-allocating budgets, orchestrating multi-channel experiments, learning from outcome data, and adapting strategy in real time. This is what marketing's most persistent, high-cost problems demand: not another content generator, but a system of tightly woven agents driving decisions, resource allocation, and continuous performance improvement.
What distinguishes the next phase is a shift from "intelligence as output" to intelligence as process. Memory, causality, experimentation, and cost-benefit analysis become first-class features. The measure of progress is no longer the parameter count or leaderboard score, but the quality of orchestration: how well the system situates intelligence within real-world, high-value feedback loops. Here, applied intelligence ceases to be an abstraction and becomes an operator—learning, compounding, and adapting as the terrain shifts.
The next wave of defensibility comes from tackling "slice-of-pain" problems—the kinds of messy, high-stakes domains in marketing where cost of error is nontrivial, where workflows span channels, platforms, and feedback cycles, and where existing automation repeatedly breaks down. It's here that agentic systems—AI processes with memory, iterative optimization, embedded experimentation, and cost/benefit awareness—move from flashy demo to mission-critical operator.
The plateau is real, but it's not a dead-end; it's more like a mesa, and we'll find our way to the next incline. Past tech waves teach us that after the hype settles, the real work begins – integrating the tech, refining it, finding its best fit. We're in that phase now with AI. The frenzy of 2022-2023 is giving way to a sober, industrious 2024-2025. AI isn't magic; it's engineering. And as we temper our expectations, we might actually deliver on them better.
The next movement is about building agency: tying intelligence into continuous, purposeful streams—agents that reason across steps, remember context, weigh costs and benefits, and flexibly serve goals over time. Progress is now about agentic infrastructure: training, prompting, chaining, workflow building, embedding cost-benefit and causal reasoning models—approaches that force AI to move from static response to dynamic, contextual, even proto-motivated behavior. This "binding" of intelligence into useful, agentic action is, paradoxically, the real bottleneck—and the real frontier.
The field is maturing into building useful plateaus—middle layers where intelligence becomes less abstract and more emplaced in real-world action, incentive, and memory.
Lastly, in contemplating "intelligence" itself, perhaps we'll realize it's not a single dimension where humans are at 100 and AI is climbing up from 0 to 100. Instead, intelligence is a multifaceted space of abilities and understanding. In some parts of that space, AIs already far exceed us (try multiplying six-digit numbers in your head—AI wins). In other parts, they lag (common sense reasoning, adaptive planning in novel real-world situations). The future will likely see a blend of human and machine intelligence each doing what it's best at. Rather than replacing us, AIs will complement us—if we are wise about how we implement them.
There's plenty of work optimizing and using what we have (which is already pretty amazing, plateau or not). As one era of dizzying AI progress transitions into an era of consolidation and application, we have a chance to ground our understanding of intelligence in real-world value. In doing so, we just might redefine intelligence itself: not as an absolute, God-like problem-solving power, but as something inseparable from purpose, context, and use. And that redefinition will ensure that when truly advanced AI comes, it will be not an alien overlord or a mere curiosity, but a tool as deeply woven into our lives as electricity—powerful, yes, but ultimately empowering, in a human-centric way.
With real, tangible improvements to human life. That, more than any hype, is the goal worth chasing. Onward.













